Introduction: Beyond the Magic
Machine learning and artificial intelligence are surrounded by an aura of technological magic. We hear about AI recognizing images, powering autonomous systems, and making complex forecasts, and it's easy to assume the process is as futuristic as the outcome. The reality, however, is often more disciplined, practical, and surprising than the hype suggests.
Creating a valuable machine learning model isn't about unleashing a black box of code and hoping for the best. It's a methodical engineering process that starts long before a single line of a model's code is written and continues long after it makes its first prediction. The most successful projects are grounded in business reality, driven by careful data preparation, and maintained through constant vigilance.
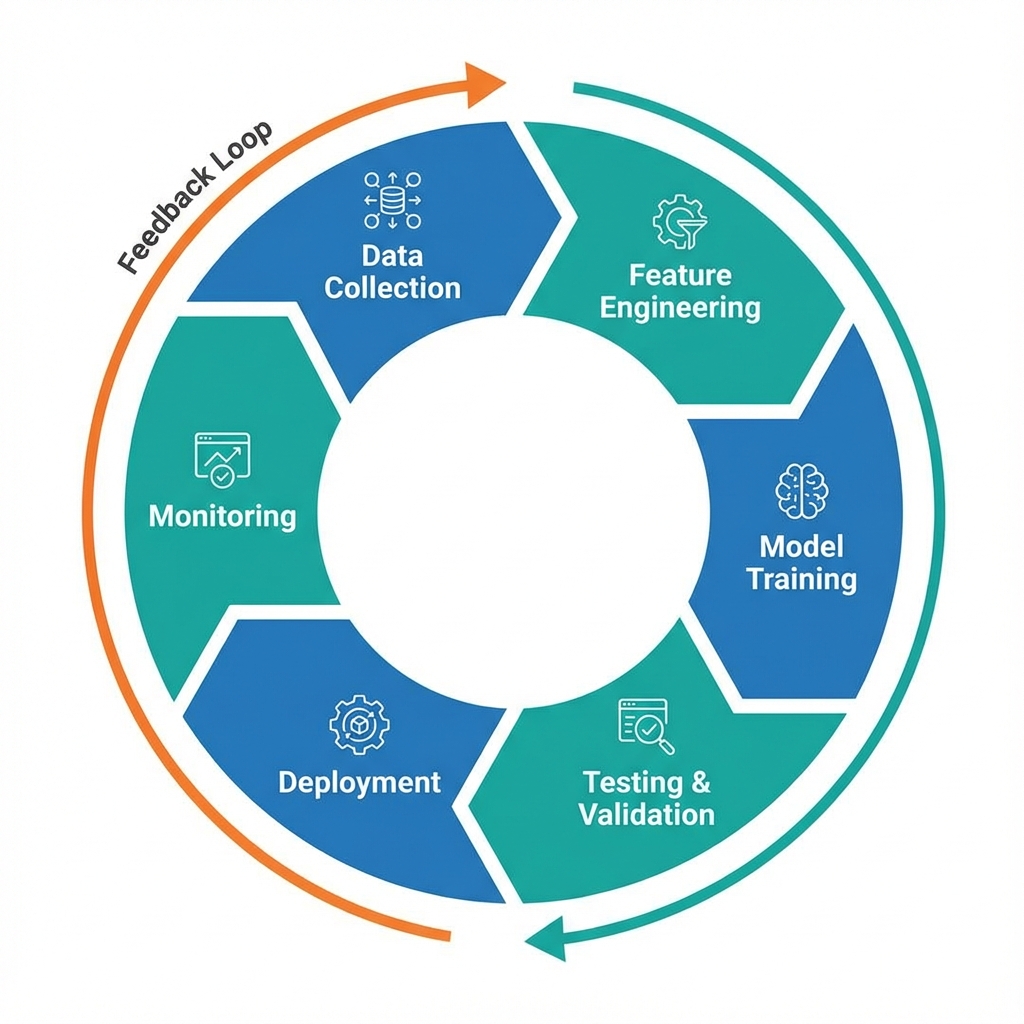 Figure 1: The Iterative Lifecycle of a Machine Learning Project
Figure 1: The Iterative Lifecycle of a Machine Learning Project
This article will pull back the curtain on five key takeaways from the machine learning trenches, revealing the practical realities of building an ML model from the ground up.
1. The First, and Most Important, Question: "Should We Even Use Machine Learning?"
Contrary to popular belief, the most crucial first step in any ML project is determining if machine learning is the right tool at all. It's tempting to jump to a cool, new technology, but every project must begin with a fundamental business problem, not a predetermined solution. Many organizational challenges are better, faster, and more cost-effectively solved with other approaches.
For example, if medical image analysis is delayed due to a lack of staff, the most direct solution might be to hire more medical professionals. If that isn't cost-effective, then ML becomes a potential alternative. In other cases, traditional programming methods with a number of conditional evaluations might make more sense. The entire process must start with the business need, and only then should ML be considered as one of several potential tools. Being prepared to say "no" to ML isn't a failure; it's a sign of a mature, problem-focused approach.
2. Most Real-World ML is Less "Sci-Fi" and More "Spreadsheet"
When people think of machine learning, they often picture exciting, visual applications like image classification or object recognition in photos and videos. While these are powerful capabilities, they don't represent the day-to-day reality for most ML practitioners. The vast majority of organizations run on data that looks more like a spreadsheet than a photograph.
This "tabular data"—information organized in rows and columns—is the bedrock of most business operations. For a telecommunications company, the goal might be churn prediction. The business value isn't just knowing who might leave; it's that "if we could accurately predict which customers are likely to leave, we can offer targeted incentives to keep them, at a price point that is still profitable and cheaper than acquiring a new customer."
For a real estate firm, the challenge is initial pricing. An ML model can "...provide an initial estimate based on property characteristics to start the marketing process without the delay and cost of an initial physical visit." Understanding this reality is critical, as the most immediate opportunities are likely hiding in the databases and spreadsheets you already have.
3. A Big Part of the Job is Throwing Data Away
There's a common intuition that in the world of big data, "more is always better." When it comes to training a machine learning model, this couldn't be further from the truth. A critical data preparation step called 'feature engineering' often involves a data scientist intentionally dropping or removing features (columns) from the dataset.
There are two primary reasons for this: 1. Irrelevance & Noise: A customer's personal account number holds no predictive value in determining if a transaction is fraudulent and should be removed. 2. Redundancy: If two columns increase and decrease in near-perfect alignment, keeping both adds more complexity than signal.
But feature engineering is a two-way street. Sometimes the job isn't about removing data, but creating new, more valuable features from existing data. For example, a dataset might contain an "account creation date." A data scientist might recognize that the raw date isn't as useful as the account's tenure. They can then synthesize a new feature, "account age in days," which may be far more predictive for the model.
4. To See if a Model Works, You Intentionally Hide Data From It
How do you know if your newly trained model is any good? The surprising answer is that you test it with data it has never seen before. During the development process, a data scientist will split the dataset, using a large portion for training the model but intentionally holding back the rest for evaluation. A common approach is a 70/30 split, where 70% of the data is used for training and 30% is held back for testing.
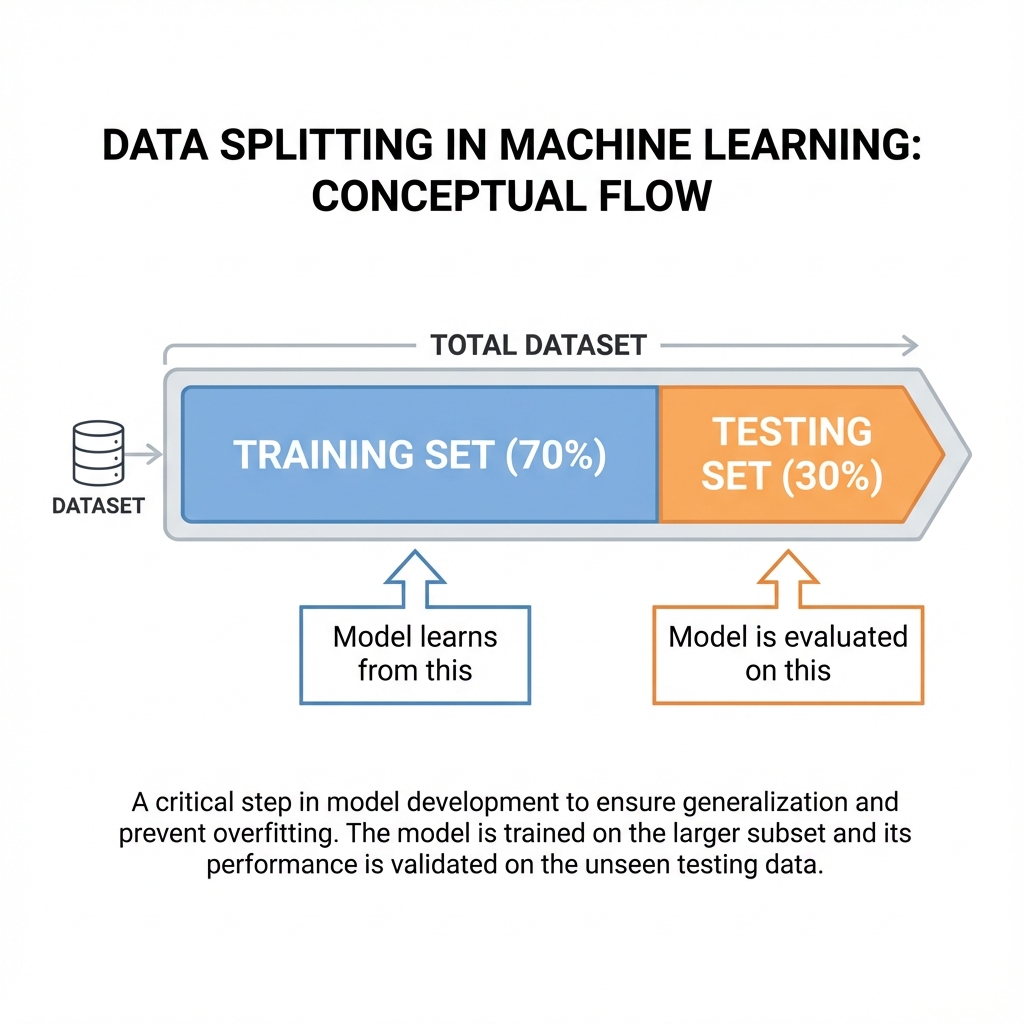 Figure 2: The Critical Train/Test Split Concept
Figure 2: The Critical Train/Test Split Concept
This held-back data serves as an objective benchmark. Once the model is trained, the scientist feeds it the input features from this unseen data and compares the model's predictions to the actual, known outcomes (the "ground truth"). This is the only way to get a true measure of the model's accuracy. A model that simply memorized its training data is useless; its real value is proven only by its performance on data it was never trained on.
5. A "Finished" Model Is Never Actually Finished
Deploying a model into production isn't the end of the machine learning pipeline; it's just another step in a continuous cycle. A model's accuracy is not static. Its performance will inevitably degrade over time in a phenomenon known as "model drift." This is not a failure, but an expected outcome, because the real world is constantly changing—"data becomes historical and user patterns change over time."
To combat this, a robust ML process requires continuous monitoring. By establishing a "feedback loop" that compares a model's live predictions to actual outcomes, an organization can detect when drift is occurring. This loop signals when it's time to go back, gather newer data, and retrain the model to keep it relevant and accurate. Machine learning is not a one-time project with a final deliverable, but a living, iterative lifecycle that must be actively maintained.
Conclusion: From Magic to Method
Successful machine learning isn't a magical act of technological alchemy. It is a disciplined, iterative engineering process that demands a sharp focus on the business problem, a practical approach to data, and a commitment to continuous improvement. By understanding these real-world principles, we can move beyond the hype and begin to see ML for what it truly is: a powerful and methodical tool for solving tangible problems.